Here’s a guide to my lazy setup for running multiple Firefox tabs in the same
session over different networks using the magic of SOCKS.
The use-case is that I sometimes want to access a web app or page which is only
accessible via a specific network (i.e., my work network or Tor), but I most
definitely don’t want the rest of my browsing traffic going through there.
The general idea is to use long-running SSH tunnels to provide one or more
SOCKS5 proxies that can be used by Firefox (or your browser of choice). SOCKS is
a protocol that allows applications to request connections through a proxy
server. Applications, such as Firefox, must be configured to use it.
Generally, to do this manually, you’d first SSH with dynamic forwarding into a host on the desired network:
ssh -D1080 user@host
…and now a SOCKS proxy on localhost port 1080 is ready to forward connections
to the remote host. Tor also provides a SOCKS proxy that can be used in
much the same way by default on port 9050. This does not conflict with Tor Browser,
which runs its own Tor daemon listening on port 9051, separate from the system Tor.
So, to use the proxy in a browser, the browser’s network settings should be changed to resemble something like this:
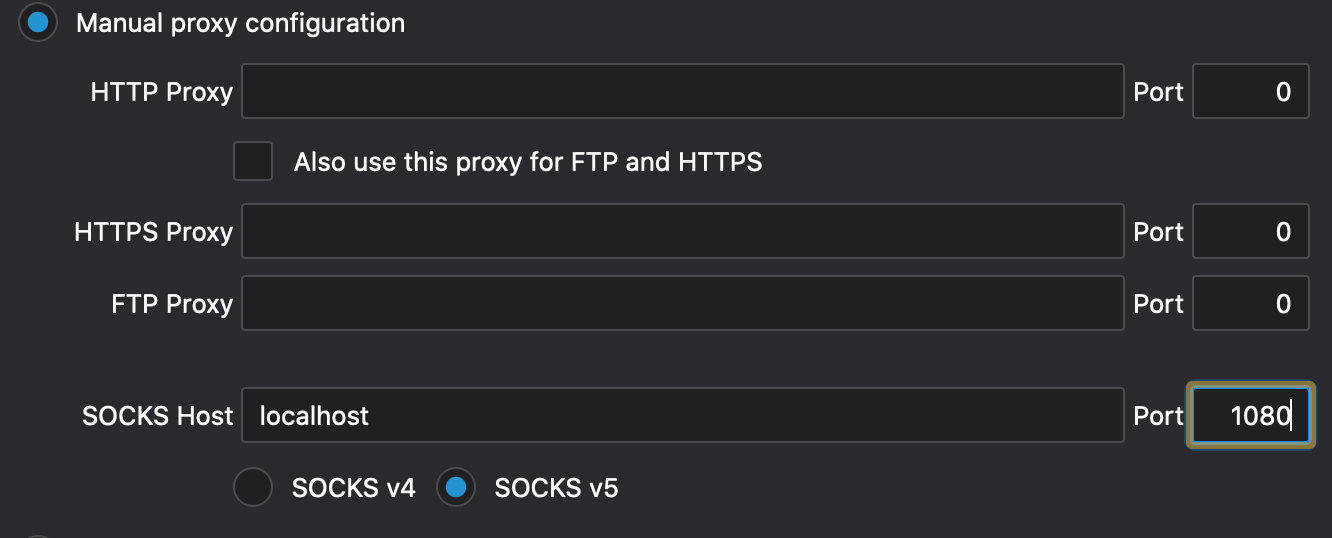
Firefox also has a checkbox for proxying DNS requests through the same connection.
It’s a good idea to proxy your DNS requests because 1) the remote DNS resolver might know names of resources you can’t access
locally and 2) due to the prevalence of CDNs in the Internet, the IP addresses
obtained this way will often correspond to servers physically closer to the
tunnel endpoint, speeding up connections.
These settings could be saved under a separate Firefox profile that can be
fired up whenever the SSH connection is active. Any browser requests will be
forwarded to the network of the host you’re SSHed into.
Now, this is an easy substitute for a VPN, but still requires launching a new
SSH connection and browser instance every time you want to browse via the
remote network. Plus, multiple networks mean multiple profiles or multiple SSH
connections which is a pain to manage.
Enter Firefox containers and autossh. The first is an extension that allows you
to keep website data, cookies, and cache separate between tabs and websites by assigning them to different containers.
The second is a way to maintain an SSH tunnel indefinitely.
The way to glue them together is Container Proxy, another Firefox extension that allows per-container proxy settings.
Here’s how it works:
Autossh and Tor
This is a wrapper around ssh to keep tunnels open indefinitely in the background. It can use any SSH option or config.
For simplicity, I have the following config specified for my proxy host in ~/.ssh/config:
Host pxhost
Hostname pxhost.example.com
ServerAliveInterval 30
ServerAliveCountMax 3
DynamicForward 1080
This command will run autossh in the background, forever keeping the
connection alive.
autossh -M 0 -f -N pxhost
To persist this on reboot, I use a systemd service file for Linux and a @reboot cronjob for macOS.
I also have Tor configured to run at startup, allowing me to use it alongside other connections. Tor can run as a service on distros using systemd.
On macOS, I modified the .torrc file in my home directory to include RunAsDaemon 1, and just running tor with no options on the command line starts
the SOCKS proxy.
Firefox Multi-Account Containers
The extension can be found in the official Firefox store.
I have three containers: a Direct container for day-to-day browsing without a proxy, a Work container for accessing some infrastructure at work via an SSH connection into my work computer,
and a Tor container for looking at .onion addresses or other web pages over Tor:
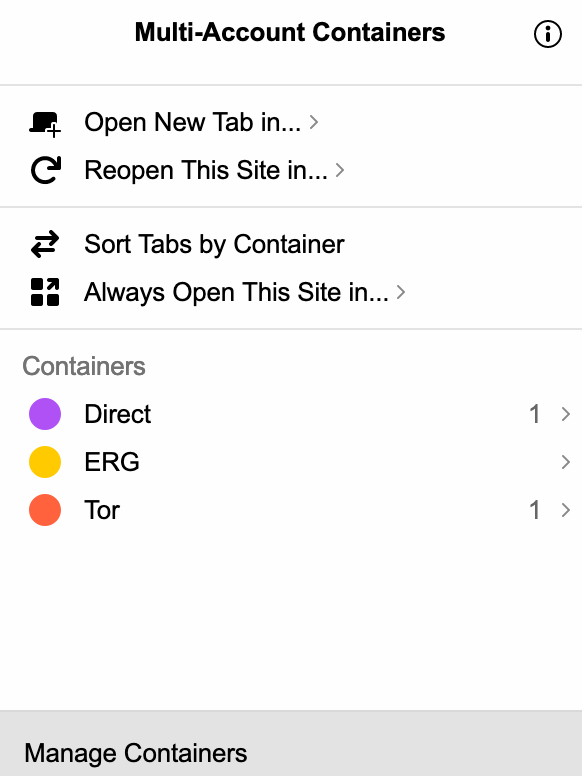
Tabs opened in each container are colour coded, and easy to keep track of.
An important note about the Tor container: using Tor as a proxy and not using
Tor Browser does not provide anonymity, because any other browsers will leak
client information allowing 3rd parties to identify users. I do this mostly for
convenience and sometimes to avoid eavesdropping from my ISP. However, if you
want anonymity, USE TOR BROWSER!
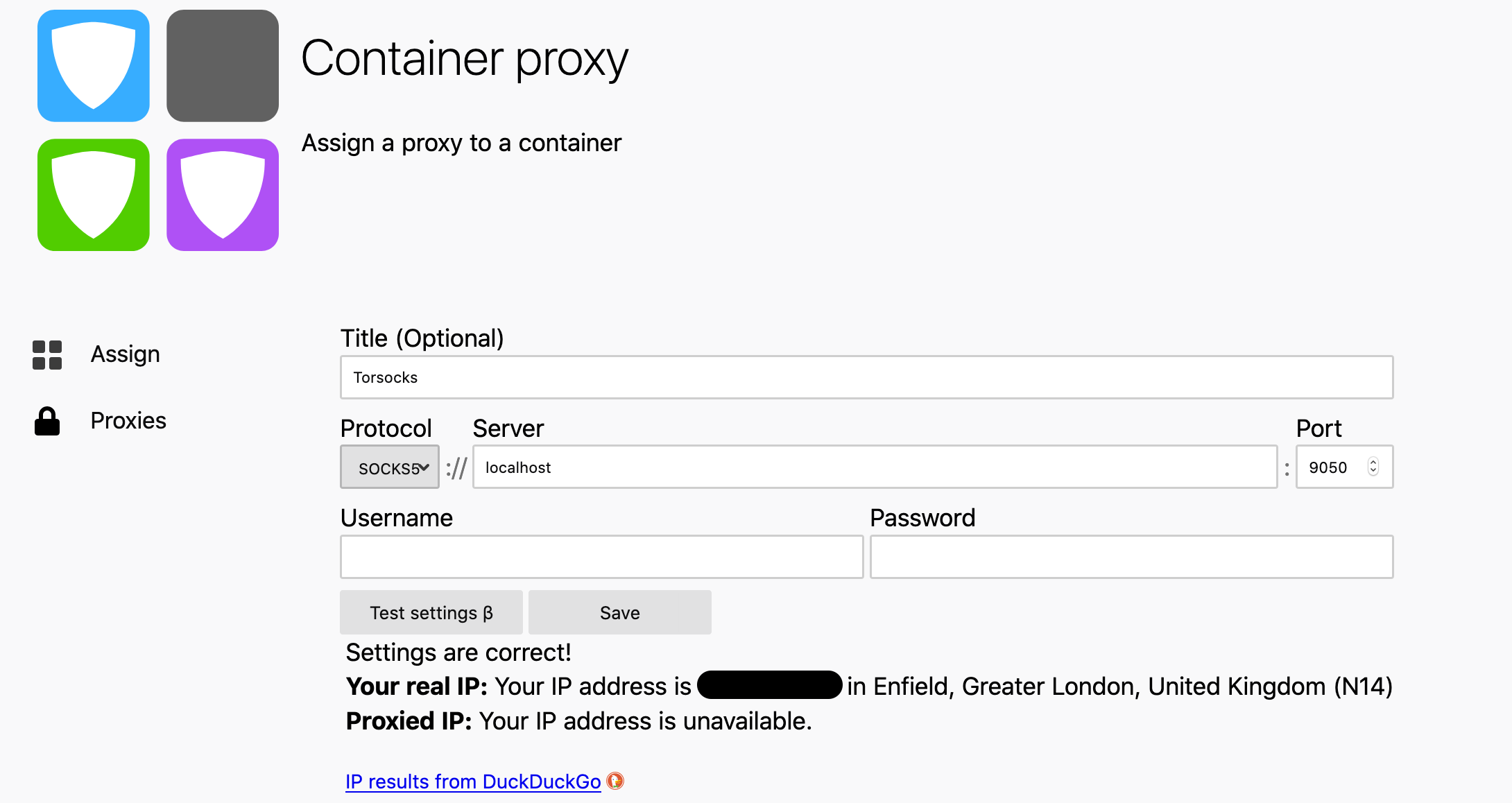
Container Proxy
Proxies for containers are not supported natively in the official Firefox
extension. At the moment, another extension is required to make the containers
use the tunnels. While not checked by Mozilla, this is open source and the code is auditable at
https://github.com/bekh6ex/firefox-container-proxy.
It lets you configure and test the proxies with DuckDuckGo, and assign them to containers:
If the tunnels are set up to persist on reboot, and your Firefox profile is not entirely erased with the latest update, this is how it looks/works:
That’s it. Containers are cool. Use more containers, before Mozilla dies off.